
今回はこれをやります!
ExcelのURLリストから、複数のサイトを自動で巡回できるプログラムを作成する!
今回は、外務省、総務省、財務省のWebページを自動で巡回して、新着情報を収集する
![]()
参考文献

準備
- まずは事前にそれぞれのWebページをChromeブラウザで表示して、
要素を取得するためのCSSセレクタを調べる
 suno
sunoやり方はこちらを参照
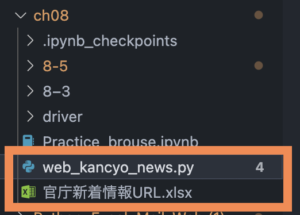
実際のWebページから情報を読み取る! - 「サイト名」、「新着情報URL」、「調べたCSSセレクタ」をExcelファイルにまとめて、
これから作成しするPythonファイルと同じフォルダに保存する

(ファイル配置)
Pythonを使ったコーディング
from selenium import webdriver
from selenium.webdriver.common.by import By
import openpyxl
# URLリストの読み込み
wb = openpyxl.load_workbook("官庁新着情報URL.xlsx")
ws = wb["Sheet1"]
url_list = []
for row in ws.iter_rows(min_row=2):
if row[0].value is None:
break
value_list = []
for c in row:
value_list.append(c.value)
url_list.append(value_list)
# chromedriverがある場所
driver_path = "driver/chromedriver"
# webdriverの作成
driver = webdriver.Chrome(executable_path=driver_path)
# 要素が見つからない場合は10秒待つように設定
driver.implicitly_wait(10)
# 読み取り結果のリスト
data_list = []
for url in url_list:
kancyo_name = url[0]
kancyo_url = url[1]
css_date = url[2]
css_links = url[3]
# 新着情報のページを開く
driver.get(kancyo_url)
# 最新の日付
date_elem = driver.find_element(By.CSS_SELECTOR, css_date)
date_text = date_elem.text
# 最新の新着情報のa要素
links = driver.find_elements(By.CSS_SELECTOR, css_links)
for link in links:
link_text = link.text
link_url = link.get_attribute("href")
data_list.append([kancyo_name, date_text, link_text, link_url])
# ブラウザを閉じる
driver.quit()
# 新しいブックに保存
wb_new = openpyxl.Workbook()
ws_new = wb_new.worksheets[0]
row_num = 1
for data in data_list:
# 官庁名
ws_new.cell(row_num, 1).value = data[0]
# 日付
ws_new.cell(row_num, 2).value = data[1]
# テキスト
ws_new.cell(row_num, 3).value = data[2]
# リンク先
ws_new.cell(row_num, 4).value = data[3]
row_num = row_num + 1
wb_new.save("官庁新着情報.xlsx")
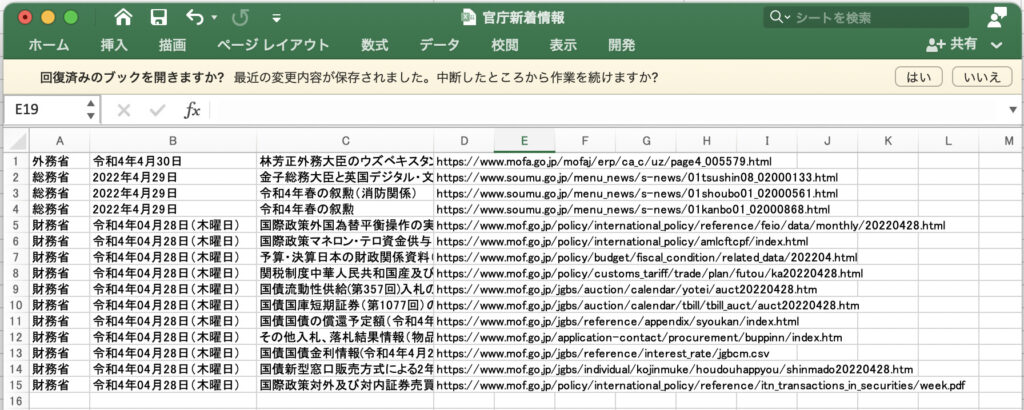
結果
プログラムを実行するとChromeブラウザが起動して、外務省⇨総務省⇨財務省の順にWebページが表示された後、自動的に閉じる
(保存されたExcelファイル)
ポイント
◆まずは「官庁情報URL.xlsx」を読み込んで、url_listに入れておく
- iter_rows()を利用してセルを1行ずつ読み込む
最後尾の空調を読み込まないように、
row[0].value is Noneで空行を検知したら読み込みを終了する
◆それぞれのWebページを開いて情報を読み取る
- 「Webページを開く⇨要素の検索⇨要素から情報の読み取り」の一連の処理を
官庁ごとに繰り返す。 - WebページのURLとCSSセレクタは、url_listに入れておいたデータをfor文で1つずつ取り出して使う
- 全てのWebページから情報を読み取りdata_listに追加したら、ブラウザをquit()で閉じる
◆最後にdata_listの内容をExcelファイルに保存
- 1行目に官庁名を入力して、1行ずつ「官庁名、日付、テキスト、リンク先」を書き込む
- 全てのデータを書き込んだらファイル名をつけて保存
Webページのスクショを保存する!
プログラムで複数のWebページを自動で巡回すると、画面が次々と切り替わるため、
Webページがどのような状態であったかが分かりにくい。
そのような時、「スクリーンショット」を札軽視、保存すると便利!
▼Webページのスクショを撮影 drier.save_screenshot(ファイル名)
今回の場合は、次のように各官庁のWebページを巡回するfor文の中に、コードを1行追加するだけで、スクリーンショットを保存しておける。
ここでは拡張子に「.png」をつけて、PNG形式で画像を保存!
from selenium import webdriver
from selenium.webdriver.common.by import By
import openpyxl
# URLリストの読み込み
wb = openpyxl.load_workbook("官庁新着情報URL.xlsx")
ws = wb["Sheet1"]
url_list = []
for row in ws.iter_rows(min_row=2):
if row[0].value is None:
break
value_list = []
for c in row:
value_list.append(c.value)
url_list.append(value_list)
# chromedriverがある場所
driver_path = "driver/chromedriver"
# webdriverの作成
driver = webdriver.Chrome(executable_path=driver_path)
# 要素が見つからない場合は10秒待つように設定
driver.implicitly_wait(10)
# 読み取り結果のリスト
data_list = []
for url in url_list:
kancyo_name = url[0]
kancyo_url = url[1]
css_date = url[2]
css_links = url[3]
# 新着情報のページを開く
driver.get(kancyo_url)
# 最新の日付
date_elem = driver.find_element(By.CSS_SELECTOR, css_date)
date_text = date_elem.text
# 最新の新着情報のa要素
links = driver.find_elements(By.CSS_SELECTOR, css_links)
for link in links: link_text = link.text
link_url = link.get_attribute("href")
data_list.append([kancyo_name, date_text, link_text, link_url])
#スクリーンショット撮影
driver.save_screenshot("screen_" + kancyo_name + ".png")
# ブラウザを閉じる
driver.quit()
# 新しいブックに保存
wb_new = openpyxl.Workbook()
ws_new = wb_new.worksheets[0]
row_num = 1
for data in data_list:
# 官庁名
ws_new.cell(row_num, 1).value = data[0]
# 日付
ws_new.cell(row_num, 2).value = data[1]
# テキスト
ws_new.cell(row_num, 3).value = data[2]
# リンク先
ws_new.cell(row_num, 4).value = data[3]
row_num = row_num + 1
wb_new.save("官庁新着情報.xlsx")け
結果
同フォルダに、ブラウザで画面が遷移したのち、ファイルの保存と、PNG形式でのスクショ保存される!
QRコードを作成してみよう!
QRコードの作成には、オープンソースのグラフ作成Web APIの「QuickChart」を利用する
Web APIとはWebサーバーの機能を通信を介して利用する仕組みのことで、
遠隔地からWebサーバーをアプリケーションのように利用できる。
QuickChartは次のようなURLをブラウザのアドレスバーに入力すれば簡単にQRコードを作成できる

このURLの末尾の「?」に続けて記述されている部分を
「クエリ文字列(Quely Spring)」と呼ぶよ
クエリ文字列をURLに追加することで、Webサーバーに「パラメータ=値」として渡すことができる
ここでは、変換したいテキストがQuickChartのサーバーに渡されて、その結果変換したいテキストをQRコード化した画像がブラウザに表示される
プラウザのアドレスバーに下記の様に入力すると、QRが表示される
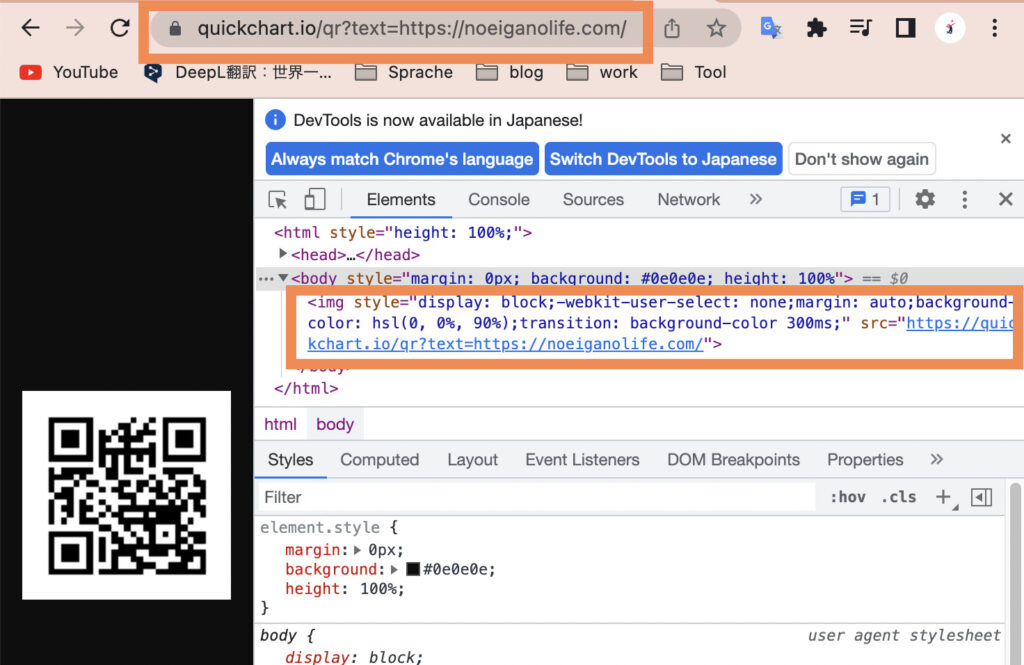
表示されているQRコードの画像の部分をChromeブラウザのデベロッパーツールで見ると、「img要素」で表示されているので、
このimg要素を検索して、その検索のスクショ保存をすれば、QRコードを画像ファイルとして保存できる
特定の要素だけを撮影するコードを書こう!
特定の要素だけを撮影する要素.screenshot
from selenium import webdriver
from selenium.webdriver.common.by import By
import openpyxl
import time
# URLリストの読み込み
wb = openpyxl.load_workbook("官庁新着情報URL.xlsx")
ws = wb["Sheet1"]
url_list = []
for row in ws.iter_rows(min_row=2):
if row[0].value is None:
break
value_list = []
for c in row:
value_list.append(c.value)
url_list.append(value_list)
# chromedriver.exeがある場所
driver_path = "driver/chromedriver"
# webdriverの作成
driver = webdriver.Chrome(executable_path=driver_path)
# 要素が見つからない場合は10秒待つように設定
driver.implicitly_wait(10)
# QRコードの作成
for url in url_list:
kancyo_name = url[0]
kancyo_url = url[1]
# QRコードをブラウザに表示
driver.get("https://quickchart.io/qr?text=" + kancyo_url)
# imgタグを取得
img = driver.find_element(By.TAG_NAME, "img")
# imgタグだけをスクリーンショット撮影
img.screenshot("qrcode_" + kancyo_name + ".png")
# 2秒間待つ
time.sleep(2)
# ブラウザを閉じる
driver.quit()ぽ
ポイント
・driver.get()の括弧の中には、「QRコード」に変換するためのQuickChartのURLを指定
⇨ブラウザにQRコードを表示する
・QRコードを表示した状態で「img要素」をfind_element()で取得して、screenshot()でスクショを撮影
実行結果
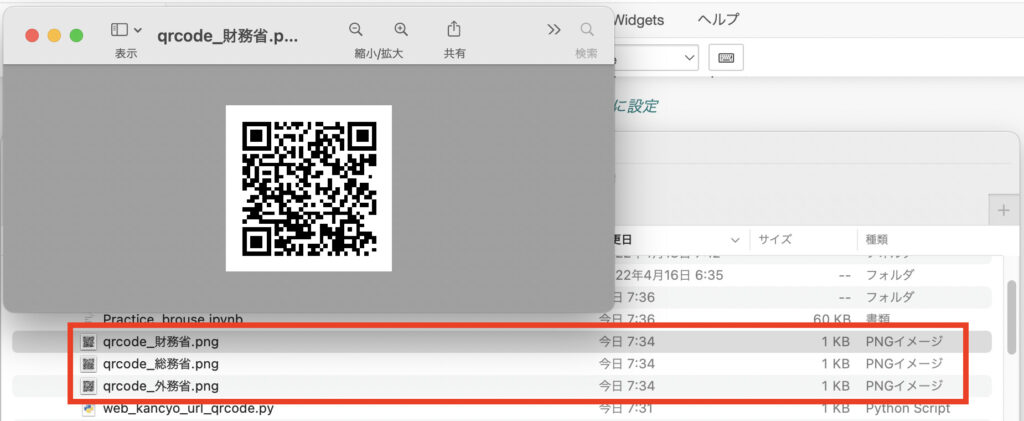
プログラムを実行すると、Chromeが起動し、次々とQRコードが表示された後に自動的に閉じる。
プログラムと同じフォルダに3つのQRコードの画像ファイルが作成される
⇨それぞれの画像をスマートフォンのカメラで読み込ませれば、目当てのページのURLが変換されたかチェックできる
Pythonで自動アクセスするときに注意すること
相手のサーバーに負荷をかけない
⇨Webサイトに大量のアクセスを行うと、相手のサーバーに負荷を与えてしまう。
そうならないように十分なアクセス感覚を設定し、何度かに分けてアクセスするなど対策を講じて相手の業務を妨害しないように注意しよう!
今回はここまで
それではまた!
sunoでした
![]()




コメント